 My web spider is based on PHP with Curl lib. With Curl, it is easy to make HTTP request with many configurable options just like using a simple web browser or much more flexible.
My web spider is based on PHP with Curl lib. With Curl, it is easy to make HTTP request with many configurable options just like using a simple web browser or much more flexible.At first, there'r 2 areas that I need to implement.
1. HTML to text content extraction2. Thai contents/ localization detection
With GeoIP, I can simply determine the physical location of an IP address but it is much more complicated to detect Thai contents.
In case of UTF-8, I can easily look up for characters in Thai Block (U+0E00 - U+0E7F).
See UTF-8 Thai block: http://www.utf8-chartable.de/unicode-utf8-table.pl?start=3584&number=128&utf8=0x

However, there are possibilities that the content was encoded in CP-874 (Windows), TIS-620 (Modern) or ISO-8859-1/ISO-8859-11 (Old age, since the beginning of the web). It is much more complicated to detect all these encodings at once.
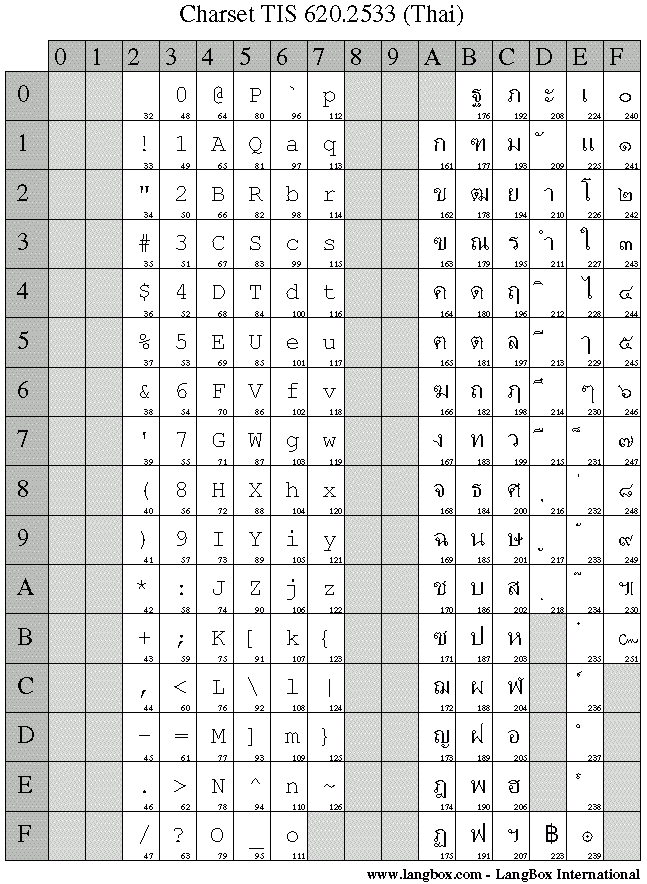 |
| TIS-620 |
 |
| ISO-8859-11 |
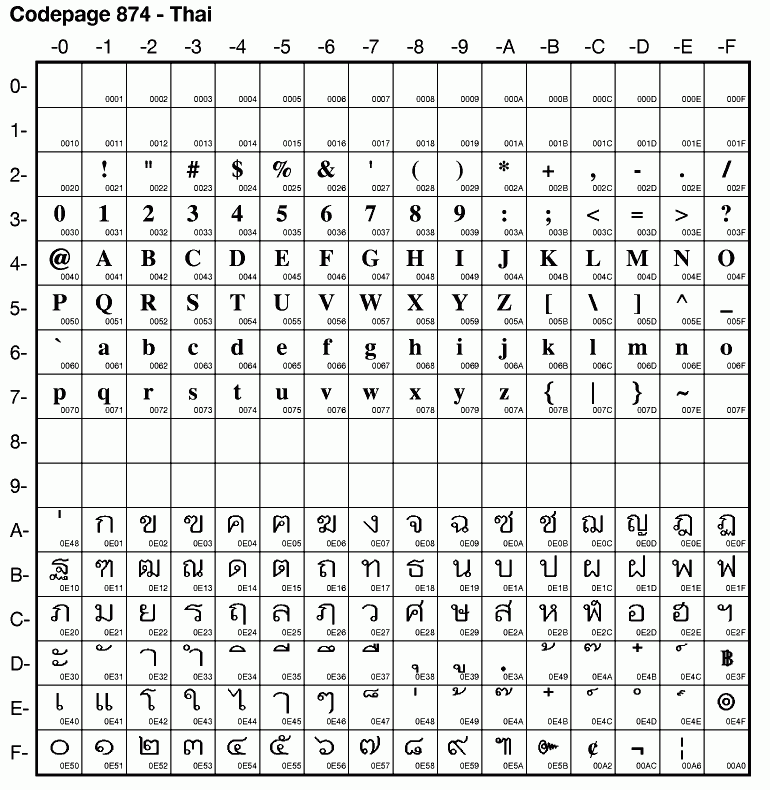 |
| CP-874 |
I do notice some hole (unused characters) in these blocks. Perhaps, it could be used to identify the block.
Another challenging topic is the database design. It'll take a while since database design will reflect the features and functionalities.
No comments:
Post a Comment